1st-order Hidden Markov Model Tagger/Disambiguator class. More...
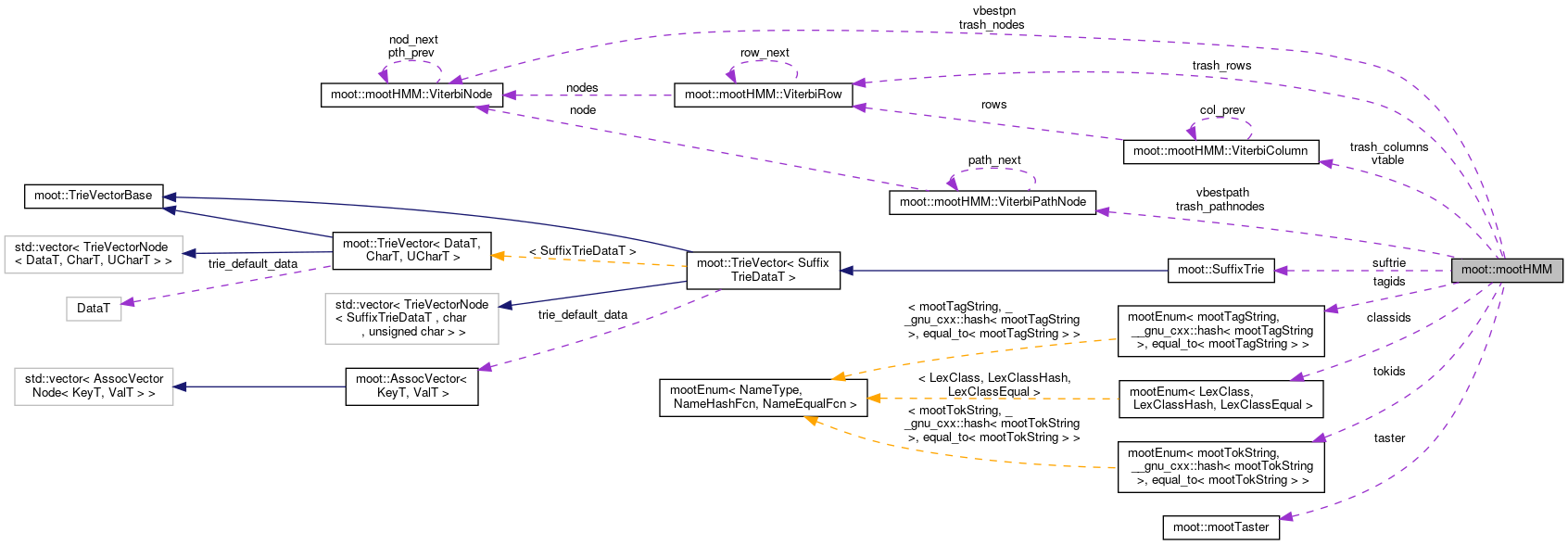
Classes | |
| struct | LexClassEqual |
| struct | LexClassHash |
| class | Trigram |
| Tag-trigram key type for HMM probability lookup table (only used if hash_ngrams is true) More... | |
| class | ViterbiColumn |
| Type for a Viterbi trellis column. More... | |
| class | ViterbiNode |
| Type for a Viterbi trellis entry ("pillar") node. More... | |
| struct | ViterbiPathNode |
| class | ViterbiRow |
| Type for a Viterbi trellis row ("current tag") node. More... | |
Public Member Functions | |
Constructor / Destructor | |
| mootHMM (void) | |
| virtual | ~mootHMM (void) |
Reset / clear | |
| void | clear (bool wipe_everything=true, bool unlogify=false) |
Binary load / save | |
| bool | save (const char *filename, int compression_level=(-1)) |
| bool | save (mootio::mostream *obs, const char *filename=__null) |
| bool | _bindump (mootio::mostream *obs, const mootBinIO::HeaderInfo &hdr, const char *filename=__null) |
| bool | load (const char *filename=__null) |
| bool | load (mootio::mistream *ibs, const char *filename=__null) |
| bool | _binload (mootio::mistream *ibs, const mootBinIO::HeaderInfo &hdr, const char *filename=__null) |
Accessors | |
| void | unknown_token_name (const mootTokString &name) |
| void | unknown_tag_name (const mootTokString &name) |
| void | unknown_class_name (const mootTagSet &tagset) |
Compilation / Initialization | |
| virtual bool | load_model (const string &modelname, const mootTagString &start_tag_str="__$", const char *myname="mootHMM::load_model()", bool do_estimate_nglambdas=true, bool do_estimate_wlambdas=true, bool do_estimate_clambdas=true, bool do_build_suffix_trie=true, bool do_compute_logprobs=true) |
| virtual bool | compile (const mootLexfreqs &lexfreqs, const mootNgrams &ngrams, const mootClassfreqs &classfreqs, const mootTagString &start_tag_str="__$", const mootTaster &mtaster=builtinTaster) |
| void | assign_ids_fl (void) |
| void | assign_ids_lf (const mootLexfreqs &lexfreqs) |
| void | assign_ids_ng (const mootNgrams &ngrams) |
| void | assign_ids_cf (const mootClassfreqs &classfreqs) |
| void | compile_unknown_lexclass (const mootClassfreqs &classfreqs) |
| bool | estimate_lambdas (const mootNgrams &ngrams) |
| bool | estimate_wlambdas (const mootLexfreqs &lf) |
| bool | estimate_clambdas (const mootClassfreqs &cf) |
| bool | build_suffix_trie (const mootLexfreqs &lf, const mootNgrams &ng, bool verbose=false) |
| bool | compute_logprobs (void) |
| void | set_ngram_prob (ProbT p, TagID t1=0, TagID t2=0, TagID t3=0) |
Top-level Tagging Interface | |
| void | tag_sentence (mootSentence &sentence) |
| virtual void | tag_io (TokenReader *reader, TokenWriter *writer) |
| virtual void | tag_stream (TokenReader *reader, TokenWriter *writer) |
Mid-level Viterbi algorithm API | |
| void | viterbi_clear (void) |
| void | viterbi_step (const mootToken &token) |
| void | viterbi_step (TokID tokid, const LexClass &lexclass, const mootTokString &toktext="") |
| void | viterbi_step (TokID tokid, ClassID classid, const LexClass &lclass, const mootTokString &toktext="") |
| void | viterbi_step (TokID tokid, const mootTokString &toktext="") |
| void | viterbi_step (const mootTokString &token_text) |
| void | viterbi_step (const mootTokString &token_text, const set< mootTagString > &tags) |
| void | viterbi_step (TokID tokid, TagID tagid, ViterbiColumn *col=__null) |
| void | viterbi_step (const mootTokString &toktext, const mootTagString &tag) |
| void | viterbi_finish (const TagID final_tagid) |
| void | viterbi_finish (void) |
| void | viterbi_flush (TokenWriter *writer, mootSentence &toks, ViterbiNode *nod) |
| void | tag_mark_best (mootSentence &sentence) |
| void | tag_mark_best (ViterbiPathNode *pnod, mootSentence &sentence) |
| void | tag_dump_trace (mootSentence &sentence, bool dumpPredict=false) |
Low-Level Viterbi Path Utilties | |
| ViterbiPathNode * | viterbi_best_path (void) |
| ViterbiPathNode * | viterbi_best_path (TagID tagid) |
| ViterbiPathNode * | viterbi_best_path (const mootTagString &tagstr) |
| ViterbiNode * | viterbi_best_node (void) |
| ViterbiNode * | viterbi_best_node (TagID tagid) |
| ViterbiNode * | viterbi_flushable_node (void) |
| ViterbiPathNode * | viterbi_node_path (ViterbiNode *node) |
Low-level Viterbi iteration utilities | |
| bool | viterbi_column_ok (const ViterbiColumn *col) const |
| ViterbiColumn * | viterbi_populate_row (TagID curtagid, ProbT wordpr=0.0, ViterbiColumn *col=__null, ProbT probmin=1.0) |
| void | viterbi_clear_bestpath (void) |
| void | _viterbi_step_fallback (TokID tokid, ViterbiColumn *col) |
Low-level Viterbi trash-stack utilities | |
| ViterbiNode * | viterbi_get_node (void) |
| ViterbiRow * | viterbi_get_row (void) |
| ViterbiColumn * | viterbi_get_column (void) |
| ViterbiPathNode * | viterbi_get_pathnode (void) |
ID Lookup | |
| TokID | token2id (const mootTokString &token) const |
| void | token2lexclass (const mootToken &token, LexClass &tok_class) const |
| LexClass * | tagset2lexclass (const mootTagSet &tagset, LexClass *lclass=__null, bool add_tagids=false) |
| ClassID | class2id (const LexClass &lclass, bool autopopulate=true, bool autocreate=true) |
Probability Lookup | |
| const ProbT | wordp (const TokID tokid, const TagID tagid) const |
| const ProbT | wordp (const mootTokString &tokstr, const mootTagString &tagstr) const |
| const ProbT | classp (const ClassID classid, const TagID tagid) const |
| const ProbT | classp (const LexClass &lclass, const mootTagString &tagstr) const |
| const ProbT | tagp (const TagID tagid) const |
| const ProbT | tagp (const mootTagString &tag) const |
| const ProbT | tagp (const TagID prevtagid, const TagID tagid) const |
| const ProbT | tagp (const mootTagString &prevtag, const mootTagString &tag) const |
| const ProbT | tagp (const Trigram &trigram, ProbT ProbZero=-1E+38) const |
| const ProbT | tagp (const TagID prevtagid2, const TagID prevtagid1, const TagID tagid) const |
| const ProbT | tagp (const mootTagString &prevtag2, const mootTagString &prevtag1, const mootTagString &tag) const |
Error reporting | |
| void | carp (const char *fmt,...) |
Debugging | |
| void | txtdump (FILE *file, bool dump_constants=true, bool dump_lexprobs=true, bool dump_classprobs=true, bool dump_suftrie=true, bool dump_ngprobs=true) |
| void | viterbi_txtdump (TokenWriter *w, int ncols=0) |
| void | viterbi_txtdump_col (TokenWriter *w, ViterbiColumn *col, int colnum=0) |
Public Attributes | |
I/O-related Flags | |
| int | verbose |
| size_t | ndots |
| bool | save_ambiguities |
| bool | save_flavors |
| bool | save_mark_unknown |
Useful Constants | |
| bool | hash_ngrams |
| bool | relax |
| bool | use_lex_classes |
| bool | use_flavors |
| TagID | start_tagid |
| ProbT | unknown_lex_threshhold |
| ProbT | unknown_class_threshhold |
| LexClass | uclass |
Smoothing Constants | |
| ProbT | nglambda1 |
| ProbT | nglambda2 |
| ProbT | nglambda3 |
| ProbT | wlambda0 |
| ProbT | wlambda1 |
| ProbT | clambda0 |
| ProbT | clambda1 |
| ProbT | beamwd |
ID Lookup Tables | |
| TokIDTable | tokids |
| TagIDTable | tagids |
| ClassIDTable | classids |
| mootTaster | taster |
Probability Lookup Tables | |
| size_t | n_tags |
| size_t | n_toks |
| size_t | n_classes |
| LexProbTable | lexprobs |
| LexClassProbTable | lcprobs |
| NgramProbHash | ngprobsh |
| NgramProbArray | ngprobsa |
| SuffixTrie | suftrie |
Viterbi Trellis Data | |
| ViterbiColumn * | vtable |
Statistics / Performance Tracking | |
| size_t | nsents |
| size_t | ntokens |
| size_t | nnewtokens |
| size_t | nunclassed |
| size_t | nnewclasses |
| size_t | nunknown |
| size_t | nfallbacks |
Protected Attributes | |
Low-level data: trash stacks | |
| ViterbiNode * | trash_nodes |
| ViterbiRow * | trash_rows |
| ViterbiColumn * | trash_columns |
| ViterbiPathNode * | trash_pathnodes |
Low-level data: temporaries | |
| TagID | vtagid |
| ProbT | vbestpr |
| ProbT | vtagpr |
| ProbT | vwordpr |
| ViterbiNode * | vbestpn |
| ViterbiPathNode * | vbestpath |
Detailed Description
All probabilities are stored internally as logarithms: this saves us a bit of runtime, and helps avoid datatype underflows.
Member Typedef Documentation
◆ TagID
| typedef mootEnumID moot::mootHMM::TagID |
Type for a tag-identifier. Zero indicates an unknown tag.
◆ TokID
| typedef mootEnumID moot::mootHMM::TokID |
Type for a token-identider. Zero indicates an unknown token.
◆ FlavorID
| typedef mootEnumID moot::mootHMM::FlavorID |
Type for a flavor-identider. 0 indicates a "normal" (e.g. alphabetic) token
◆ ClassID
| typedef mootEnumID moot::mootHMM::ClassID |
Typedef for a lexical ClassID. Zero indicates either a previously unknown class or the empty class.
◆ VerbosityLevel
Symbolic verbosity level typedef (for backwards-compatibility)
◆ LexClass
| typedef set<TagID> moot::mootHMM::LexClass |
Type for a lexical-class aka "ambiguity class". Intuitively, the lexical class associated with a given token is just the set of all a priori possible PoS tags for that that token.
◆ TagIDTable
| typedef mootEnum<mootTagString, __gnu_cxx::hash<mootTagString>, equal_to<mootTagString> > moot::mootHMM::TagIDTable |
Typedef for tag-id lookup table
◆ TokIDTable
| typedef mootEnum<mootTokString, __gnu_cxx::hash<mootTokString>, equal_to<mootTokString> > moot::mootHMM::TokIDTable |
Typedef for token-id lookup table
◆ ClassIDTable
Typedef for class-id lookup table
◆ LexProbSubTable
Type for lexical probability lookup subtable: tagid=>log(p(·|tagid))
◆ LexClassProbSubTable
Type for lexical-class probability lookup subtable: tagid=>log(p(·|tagid))
◆ LexProbTable
| typedef vector<LexProbSubTable> moot::mootHMM::LexProbTable |
Type for lexical probability lookup table: tokid=>(tagid=>log(p(tokid|tagid)))
◆ LexClassProbTable
Type for lexical-class probability lookup table: classid=>(tagid=>log(p(classid|tagid))) Really just an alias for LexProbSubtable: at some point, we should capitalize on this and make things spiffy boffo stomach-lurching fast, but that requires more information than is currently stored in our models (specifically, foreknowledge of the token->class mapping for known tokens), and an assumption that this mapping is static, which it very well might not be at some vaguely imagined unspecified future point in time.
◆ UnigramProbTable
| typedef ProbT* moot::mootHMM::UnigramProbTable |
Type for unigram probability lookup table: c-style 1d array: unigram probabilities log(p(tagid)) indexed by tagid .
Not currently used.
◆ TrigramProbHash
| typedef hash_map<Trigram,ProbT, Trigram::HashFcn, Trigram::EqualFcn> moot::mootHMM::TrigramProbHash |
Type for a trigram probability lookup table : trigram(t1,t2,t3) -> log(p(t3|<t1,t2>)) : trigram(0 ,t2,t3) ~ bigram(t2,t3)
◆ TrigramProbArray
| typedef ProbT* moot::mootHMM::TrigramProbArray |
C-style 3d array:
trigram probabilities log(p(tagid|pptagid,ptagid)) indexexed by ((n_tags*((ntags*pptagid)+ptagid))+tagid)
bigram probabilites log(p(tagid|ptagid)) indexed by ((ntags*ptagid)+tagid)
unigram probabilities log(p(tagid)) indexed by tagid .
This winds up being a rather sparse table, but it should fit well in memory even for small (~= 200 tags) tagsets on contemporary machines, and lookup is Just Plain Quick.
◆ NgramProbKey
| typedef Trigram moot::mootHMM::NgramProbKey |
◆ NgramProbHash
◆ NgramProbArray
Constructor & Destructor Documentation
◆ mootHMM()
|
inline |
Default constructor
References unknown_tag_name(), and unknown_token_name().
◆ ~mootHMM()
|
inlinevirtual |
Destructor
References _bindump(), _binload(), clear(), load(), and save().
Member Function Documentation
◆ clear()
| void moot::mootHMM::clear | ( | bool | wipe_everything = true, |
| bool | unlogify = false |
||
| ) |
Reset/clear the object, freeing all dynamic data structures. If 'wipe_everything' is false, ID-tables and constants will spared.
Referenced by ~mootHMM().
◆ save() [1/2]
| bool moot::mootHMM::save | ( | const char * | filename, |
| int | compression_level = (-1) |
||
| ) |
Save to a binary file
Referenced by ~mootHMM().
◆ save() [2/2]
| bool moot::mootHMM::save | ( | mootio::mostream * | obs, |
| const char * | filename = __null |
||
| ) |
Save to a binary stream
◆ _bindump()
| bool moot::mootHMM::_bindump | ( | mootio::mostream * | obs, |
| const mootBinIO::HeaderInfo & | hdr, | ||
| const char * | filename = __null |
||
| ) |
Low-level: save guts to a binary stream
Referenced by ~mootHMM().
◆ load() [1/2]
| bool moot::mootHMM::load | ( | const char * | filename = __null | ) |
Load from a binary file
Referenced by ~mootHMM().
◆ load() [2/2]
| bool moot::mootHMM::load | ( | mootio::mistream * | ibs, |
| const char * | filename = __null |
||
| ) |
Load from a binary stream
◆ _binload()
| bool moot::mootHMM::_binload | ( | mootio::mistream * | ibs, |
| const mootBinIO::HeaderInfo & | hdr, | ||
| const char * | filename = __null |
||
| ) |
Low-level: load guts from a binary stream
Referenced by ~mootHMM().
◆ unknown_token_name()
|
inline |
Set the unknown token name : UNSAFE!
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::unknown_name().
Referenced by mootHMM().
◆ unknown_tag_name()
|
inline |
Set the unknown tag : this tag should never appear anyways
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::unknown_name().
Referenced by mootHMM().
◆ unknown_class_name()
|
inline |
Set lexical class to use for tokens without user-specified analyses. Really just an alias for 'uclass' datum.
References assign_ids_cf(), assign_ids_fl(), assign_ids_lf(), assign_ids_ng(), moot::builtinTaster, compile(), compile_unknown_lexclass(), estimate_clambdas(), estimate_lambdas(), estimate_wlambdas(), load_model(), and tagset2lexclass().
◆ load_model()
|
virtual |
Top-level: load and compile a single model, and estimate all smoothing constants. Returns true on success, false on failure.
- Parameters
-
modelname is a model name following the conventions in mootfiles(5) start_tag_str is the string form of the boundary tag. myname name to use for warnings/errors/info do_estimate_nglambdas whether to estimate n-gram smoothing constants here do_estimate_wlambdas whether to estimate lexical smoothing constants here do_estimate_clambdas whether to estimate lexical class smoothing constants here do_build_suffix_trie whether to build a suffix trie here do_compute_logprobs whether to compute log-probabilities here
If you want to load multiple models, you will need to first load the raw-freqency objects, then call the compile(), estimate_*(), build_suffix_trie(), and compute_logprobs() methods yourself (i.e. set all of the do_* parameters to false).
Reimplemented in moot::mootDynLexHMM, and moot::mootMIParser.
Referenced by unknown_class_name().
◆ compile()
|
virtual |
Compile probabilites from raw frequency counts in 'lexfreqs' and 'ngrams'. Returns false on failure.
Referenced by unknown_class_name().
◆ assign_ids_fl()
| void moot::mootHMM::assign_ids_fl | ( | void | ) |
Assign IDs for taster; called by compile(). Allocates tokids for each flavor label and saves these in taster.
Referenced by unknown_class_name().
◆ assign_ids_lf()
| void moot::mootHMM::assign_ids_lf | ( | const mootLexfreqs & | lexfreqs | ) |
Assign IDs for tokens and tags from lexfreqs: called by compile()
Referenced by unknown_class_name().
◆ assign_ids_ng()
| void moot::mootHMM::assign_ids_ng | ( | const mootNgrams & | ngrams | ) |
Assign IDs for tags from ngrams: called by compile()
Referenced by unknown_class_name().
◆ assign_ids_cf()
| void moot::mootHMM::assign_ids_cf | ( | const mootClassfreqs & | classfreqs | ) |
Assign IDs for classes and tags from classfreqs: called by compile()
Referenced by unknown_class_name().
◆ compile_unknown_lexclass()
| void moot::mootHMM::compile_unknown_lexclass | ( | const mootClassfreqs & | classfreqs | ) |
Compile "unknown" lexical class : called by compile()
Referenced by unknown_class_name().
◆ estimate_lambdas()
| bool moot::mootHMM::estimate_lambdas | ( | const mootNgrams & | ngrams | ) |
Estimate ngram-smoothing constants: NOT called by compile().
Referenced by unknown_class_name().
◆ estimate_wlambdas()
| bool moot::mootHMM::estimate_wlambdas | ( | const mootLexfreqs & | lf | ) |
Estimate lexical smoothing constants: NOT called by compile().
Referenced by unknown_class_name().
◆ estimate_clambdas()
| bool moot::mootHMM::estimate_clambdas | ( | const mootClassfreqs & | cf | ) |
Estimate class smoothing constants: NOT called by compile().
Referenced by unknown_class_name().
◆ build_suffix_trie()
|
inline |
Build suffix trie for unknown-word handling: NOT called by compile().
References moot::SuffixTrie::build(), and compute_logprobs().
◆ compute_logprobs()
| bool moot::mootHMM::compute_logprobs | ( | void | ) |
Pre-compute runtime log-probability tables: NOT called by compile().
Referenced by build_suffix_trie().
◆ set_ngram_prob()
Low-level utility: set a (raw) n-gram probability. Used by compile()
References tag_io(), tag_sentence(), tag_stream(), and viterbi_clear().
◆ tag_sentence()
| void moot::mootHMM::tag_sentence | ( | mootSentence & | sentence | ) |
Top-level tagging interface: mootSentence input & output (destructive). Calling this method will (re-)populate the besttag datum in the sentence argument.
Referenced by set_ngram_prob().
◆ tag_io()
|
virtual |
Top-level tagging interface: TokenIO layer using sentence-level I/O
Reimplemented in moot::mootDynHMM.
Referenced by set_ngram_prob().
◆ tag_stream()
|
virtual |
Top-level tagging interface: TokenIO layer using token-level I/O
Referenced by set_ngram_prob().
◆ viterbi_clear()
| void moot::mootHMM::viterbi_clear | ( | void | ) |
Clear Viterbi state table(s)
Referenced by set_ngram_prob().
◆ viterbi_step() [1/8]
|
inline |
Step a single Viterbi iteration, mootToken version. Really just a wrapper for viterbi_step(TokID,set<TagID>).
References ntokens, moot::mootToken::text(), token2id(), token2lexclass(), moot::mootToken::toktype(), and moot::TokTypeVanilla.
Referenced by viterbi_finish(), and viterbi_step().
◆ viterbi_step() [2/8]
|
inline |
Step a single Viterbi iteration, considering only the tags in lexclass – useful if you have some a priori information on the token.
References class2id(), nunclassed, and viterbi_step().
◆ viterbi_step() [3/8]
| void moot::mootHMM::viterbi_step | ( | TokID | tokid, |
| ClassID | classid, | ||
| const LexClass & | lclass, | ||
| const mootTokString & | toktext = "" |
||
| ) |
Step a single Viterbi iteration, considering only the tags in lclass
◆ viterbi_step() [4/8]
| void moot::mootHMM::viterbi_step | ( | TokID | tokid, |
| const mootTokString & | toktext = "" |
||
| ) |
Step a single Viterbi iteration, considering all known tags for tokid as possible analyses. May be faster in cases where no futher information (i.e. set of possible tags) is available.
◆ viterbi_step() [5/8]
|
inline |
- Deprecated:
- {prefer
viterbi_step(mootToken)}
Step a single Viterbi iteration, string version. Really just a wrapper for viterbi_step(TokID tokid).
References token2id(), and viterbi_step().
◆ viterbi_step() [6/8]
|
inline |
- Deprecated:
- {prefer
viterbi_step(mootToken)}
Step a single Viterbi iteration, considering only the tags in tags.
References tagset2lexclass(), token2id(), and viterbi_step().
◆ viterbi_step() [7/8]
| void moot::mootHMM::viterbi_step | ( | TokID | tokid, |
| TagID | tagid, | ||
| ViterbiColumn * | col = __null |
||
| ) |
- Deprecated:
- {prefer
viterbi_step(mootToken)}
Step a single Viterbi iteration, considering only the tag tagid.
◆ viterbi_step() [8/8]
|
inline |
- Deprecated:
- {prefer
viterbi_step(mootToken)}
Step a single Viterbi iteration, considering only the tag tag : string version.
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), token2id(), and viterbi_step().
◆ viterbi_finish() [1/2]
|
inline |
Run final Viterbi iteration, using final_tagid as the boundary tag
References viterbi_step().
◆ viterbi_finish() [2/2]
|
inline |
Run final Viterbi iteration, using instance datum start_tagid as the final tag.
References viterbi_flush(), and viterbi_step().
◆ viterbi_flush()
| void moot::mootHMM::viterbi_flush | ( | TokenWriter * | writer, |
| mootSentence & | toks, | ||
| ViterbiNode * | nod | ||
| ) |
Run final Viterbi iteration, using final_tagid as the boundary tag
Referenced by viterbi_finish().
◆ tag_mark_best() [1/2]
|
inline |
Mid-level tagging interface: mark 'best' tags in sentence structure for the current best Viterbi path as returned by viterbi_best_path(). Fills besttag datum of each TokTypeVanilla element of sentence. Before calling this method, you should have done following:
- called
viterbi_clear()to initialize the Viterbi trellis. - called
viterbi_step(mootToken)once for each element ofsentence. - called
viterbi_finish()to push the boundary tag onto the Viterbi trellis.
- Parameters
-
sentence (partial) sentence to mark; TokTypeVanilla elements should correspond 1:1 with the ViterbiColumn*s in vtable
References tag_dump_trace(), and viterbi_best_path().
◆ tag_mark_best() [2/2]
| void moot::mootHMM::tag_mark_best | ( | ViterbiPathNode * | pnod, |
| mootSentence & | sentence | ||
| ) |
Mid-level tagging interface: mark 'best' tags in sentence structure for path pnod: fills besttag datum of each TokTypeVanilla element of sentence. Before calling this method, you should have done following:
- called
viterbi_clear()to initialize the Viterbi trellis. - called
viterbi_step(mootToken)once for each element ofsentence. - called
viterbi_finish()to push the boundary tag onto the Viterbi trellis.
- Parameters
-
pnod serialized best path for sentence sentence (partial) sentence to mark; TokTypeVanilla elements should correspond 1:1 with the path in pnod
◆ tag_dump_trace()
| void moot::mootHMM::tag_dump_trace | ( | mootSentence & | sentence, |
| bool | dumpPredict = false |
||
| ) |
Mid-level tagging interface: dump verbose trace to sentence (destructive). Calling this method will add verbose trace information as comments to sentence. Same caveats as for tag_mark_best().
Referenced by tag_mark_best().
◆ viterbi_best_path() [1/3]
|
inline |
Get current best path (in input order), considering all current tags
References viterbi_best_node(), and viterbi_node_path().
Referenced by tag_mark_best(), and viterbi_best_path().
◆ viterbi_best_path() [2/3]
|
inline |
Get current best path (in input order), considering only tag 'tagid'
References viterbi_best_node(), and viterbi_node_path().
◆ viterbi_best_path() [3/3]
|
inline |
Get current best path (in input order), considering only tag 'tag'
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), viterbi_best_node(), viterbi_best_path(), viterbi_flushable_node(), and viterbi_node_path().
◆ viterbi_best_node() [1/2]
| ViterbiNode* moot::mootHMM::viterbi_best_node | ( | void | ) |
Get best current node from Viterbi state tables, considering all possible current tags (all rows in current column). The best full path to this node can be reconstructed (in reverse order) by traversing the pth_prev pointers until (pth_prev==NULL) .
Referenced by viterbi_best_path().
◆ viterbi_best_node() [2/2]
| ViterbiNode* moot::mootHMM::viterbi_best_node | ( | TagID | tagid | ) |
Get best current path from Viterbi state tables resulting in tag 'tagid'. The best full path to this node can be reconstructed (in reverse order) by traversing the 'pth_prev' pointers until (pth_prev==NULL).
◆ viterbi_flushable_node()
| ViterbiNode* moot::mootHMM::viterbi_flushable_node | ( | void | ) |
Check whether the current viterbi trellis is unambiguous Returns a pointer to the unique "best" current node in the Viterbi trellis if there is only one possible node currently under consideration after considering beam-pruning parameters, or NULL if not only a single node is currently active (i.e. if the best path can conceivably still "flop" away from the current best node.)
- returned node can be passed to e.g. viterbi_node_path()
Referenced by viterbi_best_path().
◆ viterbi_node_path()
| ViterbiPathNode* moot::mootHMM::viterbi_node_path | ( | ViterbiNode * | node | ) |
Useful utility: build a path (in input order) from a ViterbiNode. See caveats for 'struct ViterbiPathNode' – return value is non-const for easy iteration.
Uses 'vbestpath' to store constructed path.
Referenced by viterbi_best_path().
◆ viterbi_column_ok()
|
inline |
Returns true iff col is a valid (non-empty) Viterbi trellis column
References _viterbi_step_fallback(), moot::mootHMM::ViterbiRow::nodes, moot::mootHMM::ViterbiColumn::rows, viterbi_clear_bestpath(), and viterbi_populate_row().
◆ viterbi_populate_row()
| ViterbiColumn* moot::mootHMM::viterbi_populate_row | ( | TagID | curtagid, |
| ProbT | wordpr = 0.0, |
||
| ViterbiColumn * | col = __null, |
||
| ProbT | probmin = 1.0 |
||
| ) |
Get and populate a new Viterbi-trellis row in column col for destination Tag-ID curtagid with lexical (log-)probability wordpr. If col is NULL (the default), a new column will be allocated.
- Returns
- a pointer to the trellis column, or
NULLon failure.
If specified, probmin can be used to override beam-pruning for non-NULL columns.
Referenced by viterbi_column_ok().
◆ viterbi_clear_bestpath()
| void moot::mootHMM::viterbi_clear_bestpath | ( | void | ) |
Clear internal vbestpath temporary
Referenced by viterbi_column_ok().
◆ _viterbi_step_fallback()
| void moot::mootHMM::_viterbi_step_fallback | ( | TokID | tokid, |
| ViterbiColumn * | col | ||
| ) |
Step a single Viterbi iteration, last-ditch effort: consider all tags in tagset. Implicitly called by other viterbi_step() methods.
Referenced by viterbi_column_ok().
◆ viterbi_get_node()
|
inline |
Returns a pointer to an unused ViterbiNode, possibly allocating a new one.
References moot::mootHMM::ViterbiNode::nod_next, and trash_nodes.
◆ viterbi_get_row()
|
inline |
Returns a pointer to an unused ViterbiRow, possibly allocating a new one.
References moot::mootHMM::ViterbiRow::row_next, and trash_rows.
◆ viterbi_get_column()
|
inline |
Returns a pointer to an unused ViterbiColumn, possibly allocating a new one.
References moot::mootHMM::ViterbiColumn::col_prev, and trash_columns.
◆ viterbi_get_pathnode()
|
inline |
Returns a pointer to an unused ViterbiPathNode, possibly allocating a new one.
References moot::mootHMM::ViterbiPathNode::path_next, and trash_pathnodes.
◆ token2id()
|
inline |
Get the TokID for a given token, using type-based lookup
References class2id(), moot::mootTaster::flavor_id(), mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), tagset2lexclass(), and token2lexclass().
Referenced by viterbi_step(), and wordp().
◆ token2lexclass()
Add tag fields of mootToken::analyses to tok_class
Referenced by token2id(), and viterbi_step().
◆ tagset2lexclass()
| LexClass* moot::mootHMM::tagset2lexclass | ( | const mootTagSet & | tagset, |
| LexClass * | lclass = __null, |
||
| bool | add_tagids = false |
||
| ) |
Convert string-form tagsets to lexical classes. If add_tagids is true, then tag-IDs will be assigned as needed for the element tags. If you specify NULL as the lexical class, a new one will be allocated and returned (you must then delete it yourself!)
- Note
lclassis NOT cleared by this method.
Referenced by token2id(), unknown_class_name(), and viterbi_step().
◆ class2id()
| ClassID moot::mootHMM::class2id | ( | const LexClass & | lclass, |
| bool | autopopulate = true, |
||
| bool | autocreate = true |
||
| ) |
Lookup the ClassID for the lexical-class lclass.
- Parameters
-
lclass lexical class whose ID is to be looked up autopopulate if true, new classes will be autopopulated with uniform distributions (implies autocreate).autocreate if true, new classes will be created and assigned class-ids.
Referenced by token2id(), and viterbi_step().
◆ wordp() [1/2]
Looks up and returns lexical probability: p(tokid|tagid) given tokid, tagid.
References moot::AssocVector< KeyT, ValT >::find().
Referenced by wordp().
◆ wordp() [2/2]
|
inline |
- Deprecated:
- {prefer direct lookup}
Looks up and returns lexical probability: p(tokstr|tagstr) given token, tag.
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), token2id(), and wordp().
◆ classp() [1/2]
Looks up and returns lexical-class probability: p(classid|tagid)
References moot::AssocVector< KeyT, ValT >::find().
Referenced by classp().
◆ classp() [2/2]
|
inline |
- Deprecated:
- {prefer direct lookup}
Looks up and returns lexical-class probability: p(class|tag) given class, tag – no id auto-generation is performed!
References classp(), and mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id().
◆ tagp() [1/7]
Looks up and returns unigram probability: p(tagid).
Referenced by tagp().
◆ tagp() [2/7]
|
inline |
Looks up and returns unigram (log-)probability: log(p(tag)), string-version.
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), and tagp().
◆ tagp() [3/7]
Looks up and returns bigram (log-)probability: log(p(tagid|prevtagid)), given tagid, prevtagid.
References tagp().
◆ tagp() [4/7]
|
inline |
Looks up and returns bigram probability: log(p(tag|prevtag)), string-version.
References mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), and tagp().
◆ tagp() [5/7]
Looks up and returns raw trigram (log-)probability: log(p(tagid|prevtagid2,prevtagid1)), given Trigram(prevtagid2,prevtagid1,tagid), no fallback.
References moot::mootHMM::Trigram::tag1, moot::mootHMM::Trigram::tag2, moot::mootHMM::Trigram::tag3, and tagp().
◆ tagp() [6/7]
|
inline |
Looks up and returns trigram (log-)probability: log(p(tagid|prevtagid2,prevtagid1)), given prevtagid2, prevtagid1, tagid. Falls back to (interpolated) (<n)-gram values if required.
References moot::mootHMM::Trigram::tag1, moot::mootHMM::Trigram::tag2, moot::mootHMM::Trigram::tag3, and tagp().
◆ tagp() [7/7]
|
inline |
- Deprecated:
- {prefer direct lookup}
Looks up and returns trigram (log-)probability: log(p(tag|prevtag1,prevtag2)), string-version.
References carp(), mootEnum< NameType, NameHashFcn, NameEqualFcn >::name2id(), tagp(), txtdump(), viterbi_txtdump(), and viterbi_txtdump_col().
◆ carp()
| void moot::mootHMM::carp | ( | const char * | fmt, |
| ... | |||
| ) |
Error reporting
Referenced by tagp().
◆ txtdump()
| void moot::mootHMM::txtdump | ( | FILE * | file, |
| bool | dump_constants = true, |
||
| bool | dump_lexprobs = true, |
||
| bool | dump_classprobs = true, |
||
| bool | dump_suftrie = true, |
||
| bool | dump_ngprobs = true |
||
| ) |
Debugging method: dump basic HMM contents to a text file.
Referenced by tagp().
◆ viterbi_txtdump()
| void moot::mootHMM::viterbi_txtdump | ( | TokenWriter * | w, |
| int | ncols = 0 |
||
| ) |
Debugging method: dump entire Viterbi trellis to a text file
- Deprecated:
- in favor of viterbi_dump_trace()
Referenced by tagp().
◆ viterbi_txtdump_col()
| void moot::mootHMM::viterbi_txtdump_col | ( | TokenWriter * | w, |
| ViterbiColumn * | col, | ||
| int | colnum = 0 |
||
| ) |
Debugging method: dump single Viterbi column to a text file
- Deprecated:
- in favor of viterbi_dump_trace()
Referenced by tagp().
Member Data Documentation
◆ verbose
| int moot::mootHMM::verbose |
Verbosity level. See VerbosityLevel typedef. Default=1. Not yet respected by all warnings.
◆ ndots
| size_t moot::mootHMM::ndots |
Print a dot for every ndots tokens processed if reporting progess. Default=0 (no dot printing).
◆ save_ambiguities
| bool moot::mootHMM::save_ambiguities |
Add contents of Viterbi trellis to analyses members of mootToken elements on tag_mark_best()
◆ save_flavors
| bool moot::mootHMM::save_flavors |
Add flavor names to analyses members of mootToken elements on tag_mark_best()
◆ save_mark_unknown
| bool moot::mootHMM::save_mark_unknown |
Mark unknown tokens with a single analysis '*' on tag_mark_best()
◆ hash_ngrams
| bool moot::mootHMM::hash_ngrams |
Whether to store tag n-gram probabilities in a slow but memory-friendly hash, as opposed to a dense array.
- Warning
- Using the default (false) requires O(n_tags^3) memory space for the tag n-gram probability table.
◆ relax
| bool moot::mootHMM::relax |
Whether to interpret token pre-analyses as "hints" (relax==true) or hard restrictions (relax==false). Default (as of moot version >= 2.0.8-1): true.
◆ use_lex_classes
| bool moot::mootHMM::use_lex_classes |
Whether to use class probabilities (Default=true)
- Warning
- Don't set this to true unless your input files actually contain a priori analyses generated by the same method on which you trained your model; otherwise, expect abominable accuracy.
◆ use_flavors
| bool moot::mootHMM::use_flavors |
Whether to use heuristic regex-based token "flavors" (Default=true).
◆ start_tagid
| TagID moot::mootHMM::start_tagid |
Boundary tag, used during compilation, viterbi_start(), and viterbi_finish() This gets set by the start_tag_str argument to compile(). Whatever it is, it should be consistend with what you trained on. Default = "__$" .
◆ unknown_lex_threshhold
| ProbT moot::mootHMM::unknown_lex_threshhold |
"Unknown" lexical threshhold: used during compilation to determine whether a token's statistics are recorded as "pure" lexical probabilities or as probabilities for the "unknown" token. This is just a raw count: the minimum number of times a token must have occurred in the training data in order for us to record statistics about it as "pure" lexical probabilities. Default=1.
◆ unknown_class_threshhold
| ProbT moot::mootHMM::unknown_class_threshhold |
"Unknown" lexical-class threshhold: used during compilation to determine whether a classes's statistics are recorded as "pure" class probabilities or as probabilities for the "unknown" class. This is just a raw count: the minimum number of times a class must have occurred in the training data in order for us to record statistics about it as "pure" lexical-class probabilities. Default=1
◆ uclass
| LexClass moot::mootHMM::uclass |
LexClass to use for unknown tokens with no analyses. This gets set at compile-time. You can re-assign it after that if you are so inclined.
◆ nglambda1
| ProbT moot::mootHMM::nglambda1 |
(log) Smoothing constant for unigrams
◆ nglambda2
| ProbT moot::mootHMM::nglambda2 |
(log) Smoothing constant for bigrams
◆ nglambda3
| ProbT moot::mootHMM::nglambda3 |
(log) Smoothing constant for trigrams
◆ wlambda0
| ProbT moot::mootHMM::wlambda0 |
(log) Smoothing constant for lexical probabilities
◆ wlambda1
| ProbT moot::mootHMM::wlambda1 |
(log) Smoothing constant for lexical probabilities
◆ clambda0
| ProbT moot::mootHMM::clambda0 |
(log) Smoothing constant for class probabilities
◆ clambda1
| ProbT moot::mootHMM::clambda1 |
(log) Smoothing constant for class probabilities
◆ beamwd
| ProbT moot::mootHMM::beamwd |
(log) Beam-search width: during Viterbi search, heuristically prune paths whose probability is <= 1/beamwd*p_best A value of zero indicates no beam pruning.
◆ tokids
| TokIDTable moot::mootHMM::tokids |
Token-ID lookup table
◆ tagids
| TagIDTable moot::mootHMM::tagids |
Tag-ID lookup table
◆ classids
| ClassIDTable moot::mootHMM::classids |
Class-ID lookup table
◆ taster
| mootTaster moot::mootHMM::taster |
regex-based flavor heuristics
◆ n_tags
| size_t moot::mootHMM::n_tags |
Number of known tags: used to compute lookup indices
◆ n_toks
| size_t moot::mootHMM::n_toks |
Number of known tokens: used for sanity checks
◆ n_classes
| size_t moot::mootHMM::n_classes |
Number of known lexical classes
◆ lexprobs
| LexProbTable moot::mootHMM::lexprobs |
Lexical probability lookup table
◆ lcprobs
| LexClassProbTable moot::mootHMM::lcprobs |
Lexical-class probability lookup table
◆ ngprobsh
| NgramProbHash moot::mootHMM::ngprobsh |
N-gram (log-)probability lookup table: hashed
◆ ngprobsa
| NgramProbArray moot::mootHMM::ngprobsa |
N-gram (log-)probability lookup table: dense
◆ suftrie
| SuffixTrie moot::mootHMM::suftrie |
string-suffix (log-)probability trie
◆ vtable
| ViterbiColumn* moot::mootHMM::vtable |
Low-level trellis structure for Viterbi algorithm
◆ nsents
| size_t moot::mootHMM::nsents |
Total number of sentenced processed
◆ ntokens
| size_t moot::mootHMM::ntokens |
Total number of tokens processed
Referenced by viterbi_step().
◆ nnewtokens
| size_t moot::mootHMM::nnewtokens |
Total number of unknown-tokens processed
◆ nunclassed
| size_t moot::mootHMM::nunclassed |
Number of classless tokens processed
Referenced by viterbi_step().
◆ nnewclasses
| size_t moot::mootHMM::nnewclasses |
Number of unknown-class tokens processed
◆ nunknown
| size_t moot::mootHMM::nunknown |
Number of totally unknown (token,class) pairs procesed
◆ nfallbacks
| size_t moot::mootHMM::nfallbacks |
Number of fallbacks in viterbi_step()
◆ trash_nodes
|
protected |
Recycling bin for Viterbi trellis nodes
Referenced by viterbi_get_node().
◆ trash_rows
|
protected |
Recycling bin for Viterbi trellis rows
Referenced by viterbi_get_row().
◆ trash_columns
|
protected |
Recycling bin for Viterbi trellis columns
Referenced by viterbi_get_column().
◆ trash_pathnodes
|
protected |
Recycling bin for Viterbi path-nodes
Referenced by viterbi_get_pathnode().
◆ vtagid
|
protected |
Current tag-id under consideration for viterbi_step()
◆ vbestpr
|
protected |
Best (log-)probability for viterbi_step()
◆ vtagpr
|
protected |
(log-)Probability for current tag-id for viterbi_step()
◆ vwordpr
|
protected |
Save (log-)word-probability
◆ vbestpn
|
protected |
Best previous node for viterbi_step()
◆ vbestpath
|
protected |
For node->path conversion
The documentation for this class was generated from the following file:
