DTA::CAB::WebServiceHowto - User documentation for DTA::CAB web-service
This document describes the use of the DTA::CAB web-service accessible at http://www.deutschestextarchiv.de/public/cab/ and its aliases http://www.deutschestextarchiv.de/demo/cab/ and http://www.deutschestextarchiv.de/cab/. The CAB web-service provides error-tolerant linguistic analysis for historical German text, including normalization of historical orthographic variants to "canonical" modern forms using the method described in Jurish (2012).
Due to legal restrictions on some of the underlying resources, not all available analysis layers can be returned by the publically accessible web-service, but it is hoped that the available layers (linguistically salient TEI-XML serialization, sentence- and word-level tokenization, orthographic normalization, part-of-speech tags, and (normalized) lemmata) should suffice for most purposes.
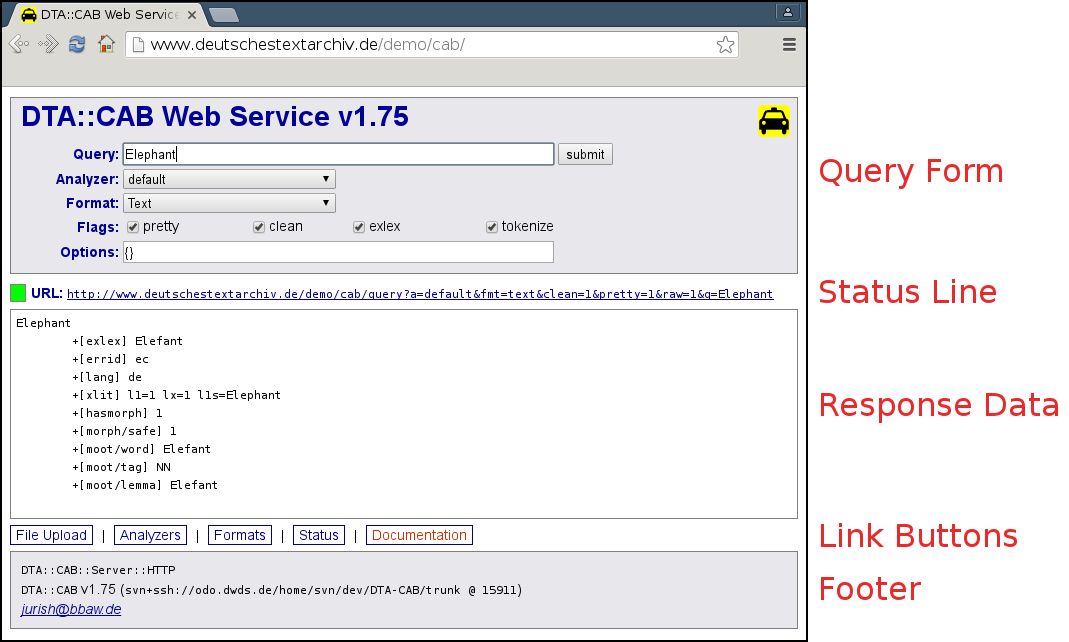
Upon accessing the top-level web-service URL ( http://www.deutschestextarchiv.de/cab/ ) in a web browser, the user is presented with a graphical interface in which CAB queries can be constructed and submitted to the underlying server. This section describes the various elements of that interface.
At the top of the web-service interface is a query form on a gray background including input fields for the CAB query parameters ("Query", "Analyzer", "Format", etc.). Each query form input element should display a tooltip briefly describing its function if you hover your mouse pointer over it in a browser. See "query Requests" in DTA::CAB::HttpProtocol for more details on supported query request parameters.
Immediately beneath the query form is a status display line ("URL line") on a white background with no border, which contains a link to the raw response data for the current query, if any. In the case of singleton (1-word) queries, the status line also contains a simple heuristic "traffic-light" indicator of the query word's morphological security status, where green indicates a "safe" known modern form, red indicates an unknown (assumedly historical) form, and yellow indicates a known modern form which is judged unsafe for identity canonicalization (typically a proper name).
Immediately below the URL line is the response data area ("data area") on a white background with a gray border, which displays the results for the current query, if any.
Below the data area are a number of static link buttons for the file upload ("File Upload") or the live user-input interface ("Live Query"), the list of analyzers supported by the underlying CAB instance ("Analyzers"), the list of I/O formats supported by the underlying CAB instance ("Formats"), administrative data for the CAB server instance ("Status"), and the CAB documentation ("Documentation").
Below the link button area is a short footer on a gray background containing administrative information about the underlying CAB server.
This section briefly describes the basic usage offered by the DTA::CAB web-service by reference to some simple examples.
Most CAB parameters in the query form are initialized with sensible default values, with the exception of the "Query" parameter itself, which should contain the text string to be analyzed. Say we wish to analyze the text string "Elephanten": simply entering this string (or copy & paste it) into the text input box associated with the "Query" parameter, and then pressing the Enter key or clicking the "submit" button will cause the query to be submitted to the underlying CAB server and the response data to be displayed in the data area: http://www.deutschestextarchiv.de/cab/?q=Elephanten
The results are displayed by default in CAB's native "Text" format, in which the first line contains the input surface form (Elephanten), and the remaining lines are the CAB attributes for the query word, where each attribute line is indicated by an initial TAB character, a plus ("+") sign, and the attribute label enclosed in square brackets ("[...]"), followed by the attribute value. Useful attributes include "moot/word" (canonical modern form), "moot/tag" (part-of-speech tag), and "moot/lemma" (modern lemma).
The example query for instance should produce a response such as:
Elephanten
+[moot/word] Elefanten
+[moot/tag] NN
+[moot/lemma] Elefant... indicating that the query was correctly normalized to the canonical modern form "Elefanten", tagged as a common noun ("NN"), and assigned the correct canonical lemma "Elefant".
Suppose we wish to take advantage of context information while normalizing a whole sentence of historical text, as described in Jurish (2012), Chapter 4. Simply enter the entire text of the sentence to be analyzed in the "Query" input, and ensure that the checkbox for the "tokenize" flag is checked, and submit the query, e.g.
EJn zamer Elephant gillt ohngefähr zweyhundert Thaler.The output now contains multiple tokens (words), where the analysis for each token begins with a line containing only its surface form (no leading whitespace). Token attribute lines (introduced by a leading TAB character) refer to the token most recently introduced. The output for the example query can be directly accessed here, and should look something like the following:
EJn
+[moot/word] Ein
+[moot/tag] ART
+[moot/lemma] eine
zamer
+[moot/word] zahmer
+[moot/tag] ADJA
+[moot/lemma] zahm
Elephant
+[moot/word] Elefant
+[moot/tag] NN
+[moot/lemma] Elefant
gillt
+[moot/word] gilt
+[moot/tag] VVFIN
+[moot/lemma] gelten
ohngefähr
+[moot/word] ungefähr
+[moot/tag] ADJD
+[moot/lemma] ungefähr
zweyhundert
+[moot/word] zweihundert
+[moot/tag] CARD
+[moot/lemma] zweihundert
Thaler
+[moot/word] Taler
+[moot/tag] NN
+[moot/lemma] Taler
.
+[moot/word] .
+[moot/tag] $.
+[moot/lemma] .The CAB web service can analyze multiple sentences as well, for example:
EJn zamer Elephant gillt ohngefähr zweyhundert Thaler.
Ceterum censeo Carthaginem esse delendam.The corresponding output can be viewed here, which should look something like:
%% $s:lang=de
EJn
+[moot/word] Ein
+[moot/tag] ART
+[moot/lemma] eine
...
.
+[moot/word] .
+[moot/tag] $.
+[moot/lemma] .
%% $s:lang=la
Ceterum
+[moot/word] Ceterum
+[moot/tag] FM.la
+[moot/lemma] ceterum
censeo
+[moot/word] censeo
+[moot/tag] FM.la
+[moot/lemma] censeo
Carthaginem
+[moot/word] Carthaginem
+[moot/tag] FM.la
+[moot/lemma] carthaginem
esse
+[moot/word] esse
+[moot/tag] FM.la
+[moot/lemma] esse
delendam
+[moot/word] delendam
+[moot/tag] FM.la
+[moot/lemma] delendam
.
+[moot/word] .
+[moot/tag] $.
+[moot/lemma] .Here, blank lines indicate sentence boundaries, and comments (non-tokens) are lines introduced by two percent signs ("%%"). The special comments immediately preceding each sentence of the form "%% $s:lang=LANG" indicate the result of CAB's language-guessing module DTA::CAB::Analyzer::LangId::Simple. The blank line between the final "." of the first sentence and the first word of the second sentence indicates that the sentence boundary was correctly detected, and the "%% $s.lang=LANG" comments indicate that the source language of both sentences was correctly guessed ("de" indicating German in the former case, and "la" indicating Latin in the latter). Due to the language-guesser's assignment for the second sentence, all words in that sentence are tagged as foreign material ("FM"), with the suffix ".la" indicating the language-guesser's output. Otherwise, no analysis (normalization or lemmatization) is performed for sentences recognized as non-German.
In addition to the default "live" query interface, the CAB web-service interface also offers users the opportunity to upload an entire document file to be analyzed and allowing the analysis results to be saved to the user's local machine. The CAB file interface is accessible via the "File Upload" button in the link area, which resolves to http://www.deutschestextarchiv.de/cab/file Suppose we have a simple plain-text file elephant.raw containing the document to be analyzed:
EJn zamer Elephant gillt ohngefähr zweyhundert Thaler.
Ceterum censeo Carthaginem esse delendam.First, save the input file elephant.raw to your local computer. Then, in the CAB file input form, click on on the "Choose File" button and select elephant.raw from wherever you saved it. Clicking on the "submit" button will cause the contents of the selected file to be sent to the CAB server, analyzed, and prompt you for a location to which the analysis results should be saved (by default elephant.raw.txt). Assuming the default options were active, you should have a result file resembling this, identical to the results displayed in the data area for the multi-sentence query example.
Due to bandwidth limitations, the CAB server currently only accepts input files of size <= 1 MB. If you need analyze a large amount of data, you will first need to split your input files into chunks of no more than 1 MB each, sending each chunk to the server individually. In this case, please refrain from "hammering" the CAB server with an uninterrupted stream of requests: wait at least 3-5 seconds between requests to avoid blocking the server for other users. Alternatively, if you need to analyze a large corpus, you can contact the Deutsches Textarchiv.
The CAB server supports a number of different analysis modes, corresponding to different sorts of input data and/or different user tasks. The various analysis modes are implemented in terms of different analysis chains (a.k.a. "analyzers" or just "chains") supported by the underlying analysis dispatcher class, DTA::CAB::Chain::DTA. The analysis mode to be used for a particular CAB request is specified by the "analyzer" or "a" parameter, which is initially set to use the "default" analysis chain (which is itself just an alias for the "norm" chain).
This section briefly describes some alternative analysis chains and situations in which they might be useful. For a full list of available analysis chains, see the list returned by the "Analyzers" button in the link area, and see DTA::CAB::Chain::DTA for a list of the available atomic analyzers and aliases for complex analysis chains. For details on individual atomic analyzers, see the appropriate DTA::CAB::Analyzer subclass documentation.
As noted above, the default "norm" analysis chain uses sentential context to improve the precision of the normalization process as described in Jurish (2012), Chapter 4. This behavior is not always desirable, however. In particular, if your data is not arranged into linguistically meaningful sentence-like units -- e.g. a simple flat list of surface types -- then no real context information is available, and the "sentential" context CAB would use would more likely hinder the normalization than help it. For such cases, the "norm1" analysis chain can be employed instead of the default "norm" chain. The "norm1" chain uses only unigram-based probabilities during normalization, so is less likely to be "confused" by non-sentence-like inputs.
Consider for example the input:
Fliegende Fliegen Fliegen Fliegenden Fliegen nach.Passing this list to the "norm1" chain inhibits context-dependent processing and results in the following
Fliegende
+[moot/word] Fliegende
+[moot/tag] ADJA
+[moot/lemma] fliegend
Fliegen
+[moot/word] Fliegen
+[moot/tag] NN
+[moot/lemma] Fliege
Fliegen
+[moot/word] Fliegen
+[moot/tag] NN
+[moot/lemma] Fliege
Fliegenden
+[moot/word] Fliegenden
+[moot/tag] NN
+[moot/lemma] Fliegende
Fliegen
+[moot/word] Fliegen
+[moot/tag] NN
+[moot/lemma] Fliege
nach
+[moot/word] nach
+[moot/tag] APPR
+[moot/lemma] nach
.
+[moot/word] .
+[moot/tag] $.
+[moot/lemma] .contrast this to the output of the default "norm" chain
Fliegende
+[moot/word] Fliegende
+[moot/tag] ADJA
+[moot/lemma] fliegend
Fliegen
+[moot/word] Fliegen
+[moot/tag] NN
+[moot/lemma] Fliege
Fliegen
+[moot/word] Fliegen
+[moot/tag] VVFIN
+[moot/lemma] fliegen
Fliegenden
+[moot/word] Fliegenden
+[moot/tag] ADJA
+[moot/lemma] fliegend
Fliegen
+[moot/word] Fliegen
+[moot/tag] NN
+[moot/lemma] Fliege
nach
+[moot/word] Nach
+[moot/tag] PTKVZ
+[moot/lemma] nach
.
+[moot/word] .
+[moot/tag] $.
+[moot/lemma] .In the above example, all instances of the surface form "Fliegen" are analyzed as common nouns (NN) with lemma "Fliege" by the unigram-based analyzer "norm1". If sentential context is considered, the second instance of "Fliegen" is correctly analyzed as a finite verb form (VVFIN) of the lemma "fliegen". Similarly, the unigram-based analyzer mis-tags "Fliegenden" as a noun rather than an attributive adjective (NN vs. ADJA) and assigns a corresponding (incorrect) lemma "Fliegende". The final particle "nach" is mis-tagged as a preposition (APPR vs. PTKVZ) by the unigram-based model, but this has no effect on the lemma assigned. Although use of the "norm1" analyzer does not alter any canonical modern forms in this example, such cases are possible.
It is sometimes useful to have a list of all known orthographic variants of a given input form, e.g. for runtime queries of a database which indexes only surface forms. For such tasks, the analysis chain "expand" can be used. To see all the variants of the surface form "Elephant" in the Deutsches Textarchiv corpus for example, one could query http://deutschestextarchiv.de/cab?a=expand&q=Elephant&tokenize=0, and expect a response something like:
Elephant
+[moot/word] Elefant
+[moot/tag] NN
+[moot/lemma] Elefant
+[eqpho] Elephant <0>
+[eqpho] Elefant <14>
+[eqpho] elephant <17>
+[eqpho] elevant <17>
+[eqpho] Elephand <18>
+[eqpho] Elevant <18>
+[eqpho] elefant <18>
+[eqpho] Elephandt <19>
+[eqpho] Elephanth <19>
+[eqrw] Elefant <0>
+[eqrw] Elephant <0>
+[eqrw] Elephandt <8.44527626037598>
+[eqrw] elefant <8.44683265686035>
+[eqrw] Elephanth <8.70806312561035>
+[eqrw] elephant <9.01417255401611>
+[eqrw] Elephand <18.6624526977539>
+[eqrw] Eliphant <18.7045001983643>
+[eqrw] Elephants <21.1982593536377>
+[eqrw] elevant <21.3945064544678>
+[eqrw] Elphant <23.2134704589844>
+[eqrw] Elesant <27.7278366088867>
+[eqrw] Elephanta <30.2710800170898>
+[eqlemma] Elefannten <0>
+[eqlemma] Elefant <0>
+[eqlemma] Elefanten <0>
+[eqlemma] Elefantin <0>
+[eqlemma] Elefantine <0>
+[eqlemma] Elephandten <0>
+[eqlemma] Elephant <0>
+[eqlemma] Elephanten <0>
+[eqlemma] Elesant <0>
+[eqlemma] elefant <0>
+[eqlemma] elephanten <0>Here, the "eqpho" attribute contains all surface forms recognized as phonetic variants of the query term, "eqrw" contains those surface forms recognized as variants by the heuristic rewrite cascade, and "eqlemma" contains the surface forms most likely to be mapped to the same modern lemma as the query term. This online expansion strategy is used by the DTA Query Lizard, and was also used by an earlier version of the DTA corpus index as described in Jurish et al. (2014), but has since been replaced there by an online lemmatization query using the "lemma" expander, in conjunction with a direct query of the underlying corpus $Lemma index.
The request includes the tokenize=0 option, which informs the CAB server that the query does not need to be tokenized, effectively forcing use of the qd parameter to the low-level service. This is generally a good idea when using single-token queries or pre-tokenized documents, since it speeds up processing.
As of DTA::CAB v1.78, the DTA Dispatcher includes specialized rewrite models (rw.1600-1700, rw.1700-1800, rw.1800-1900), and provides a number of high-level convenience chains (norm.1600-1700, norm1.1600-1700, etc.) using these models instead of the default "generic" rewrite cascade (rw) to provide canonicalization hypotheses for unknown words. The weights for the specialized rewrite models were trained on a modest number of manually assigned canonicalization pairs from the period in question extracted from the CabErrorDb error database (4,000-8,000 pair types per model), and may provide a slight improvement in canonicalization accuracy with respect to the generic model, provided that you specify the appropriate analysis chain ("Analyzer") in your request. Compare for example the outputs of the various chains for the input forms avf, Auffichten, and Büberchens:
The CAB server can be used to convert between various supported I/O Formats. In this mode, no analysis is performed on the input data (with the exception of tokenization for raw untokenized input), but the input document is parsed and re-formatted according to the selected output format. The analysis chain "null" can be selected for such tasks. To tokenize a simple text string for instance, you can select the "null" analyzer and the "text" format, and expect output such as this.
This mode of operation is mostly useful in conjunction with file upload queries to convert analyzed files. If you only need to tokenize raw text files, consider using the more efficient WASTE tokenizer web-service directly, or the CLARIN-D WebLicht tool-chainer, which offers a number of different tokenizer components.
Each analysis chain is (as the name suggests) implemented as a finite list of atomic DTA::CAB::Analyzer objects, the "component analyzers". The component analyzers in a chain are run in strict serial order (one after the other), and later-running components can and do refer to the results of analysis performed by components which have already been run. Each component analyzer populates zero or more token-, sentence-, and/or document--level attributes; typically, the component X will write the results of its analysis to the token-attribute X (e.g. the morph component populates the attribute $w.morph).
In the default DTA::CAB::Chain::DTA configuration, each individual component analyzer X can be addressed explicitly by means of the analysis chain sub.X, and the default chain of components up to and including X can be invoked by the analysis chain default.X, e.g. the morphological analysis component morph can be invoked directly by selecting the chain sub.morph, and together with its prerequisites by selecting the chain default.morph.
The following diagram is a simplified sketch of the dataflow relationships between the major "Analysis Components" for the default DTA::CAB::Chain::DTA analysis chain operating on a "raw" TEI-XML input document.
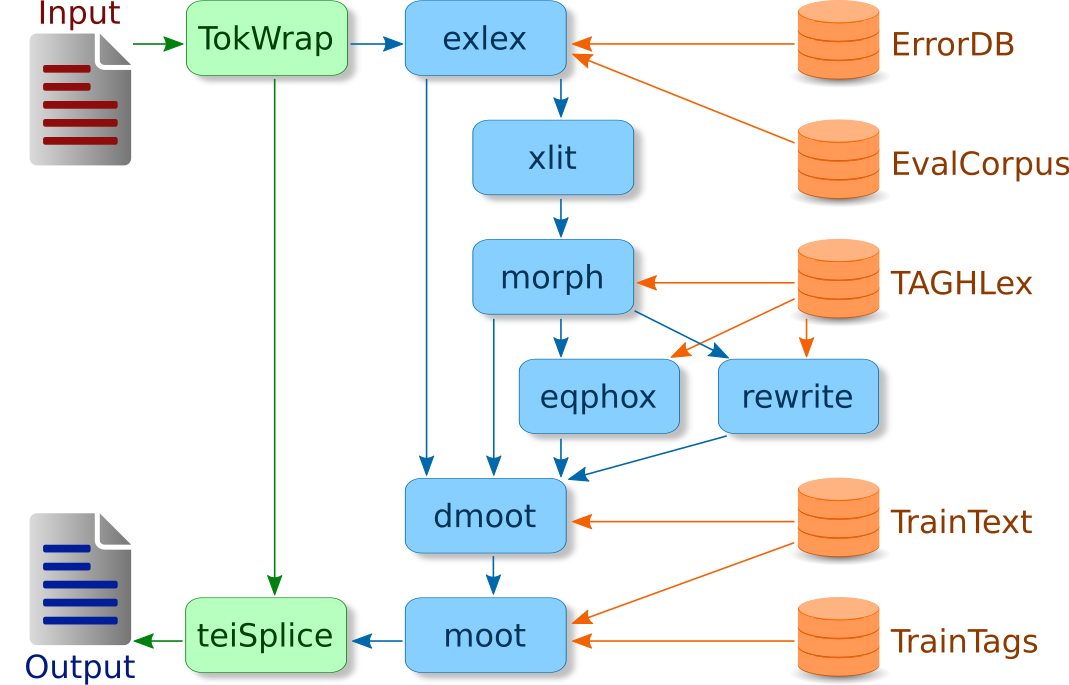
This section describes the atomic analysis components provided by the default DTA::CAB::Chain::DTA configuration.
Static type-wise analysis cache for the attributes eqphox, errid, exlex, f, lts, mlatin, morph, msafe, rw, xlit, lang, and pnd based on the most recent release of the Deutsches Textarchiv corpus, typically less than one week old.
Type-wise exception lexicon extracted from the DTA EvalCorpus and the DTA::CAB error database (demo here), typically updated weekly.
Type-wise heuristic token preprocessor used to identify punctuation, numbers, quotes, etc.
Deterministic type-wise character transliterator based on libunicruft, mostly useful for handling extinct characters and diacritics.
Deterministic type-wise phonetization ("letter-to-sound" mapping) via Gfsm transducer as described in Jurish (2012), Ch. 1.
Type-wise morphological analysis of the (transliterated) surface form via Gfsm transducer. The default DTA analysis chanin uses a modified version of the TAGH morphology FST.
Type-wise Latin pseudo-morphology for (transliterated) surface forms based on the finite word-list distributed with the "William Whitaker's Words" Latin dictionary.
Heuristics for detecting "suspicious" analyses supplied by the "morph" component (TAGH), as described in Jurish (2012), App. A.4.
Simple sentence-wise language guesser based on stopword lists extracted from the python NLTK project. Also supports the pseudo-language XY, which is typically assigned for mathematical notation, abbreviations, or other extra-lexical material.
Type-wise k-best weighted finite-state rewrite cascade conflator ("nearest neighbors") via GfsmXL transducer cascade. as described in Jurish (2012), Ch. 2
Type-wise pohonetic equivalence conflator using a GfsmXL transducer cascade; requires prior "lts" analysis. Unlike the presentation in Jurish (2012), Ch. 3, the current implementation uses a k-best search strategy over an infinite target language derived from the TAGH morphology for improved recall.
Sentence-wise conflation candidate disambiguator as described in Jurish (2012), Ch. 4. Attempts to determine the "best" modern form from the canidate conflations provided by the "exlex", "xlit", "eqphox", and "rw" components, after consideration of the properties provided by the "morph", "msafe", "mlatin", and "langid" components (e.g. sentences already identified as consisting primarily of foreign-language material will not be "forced" onto contemporary German).
Sentence-wise post-processing for the "dmoot" HMM. Mostly useful for performing morphological analysis on non-trivial canonicalizations supplied by "dmoot".
Sentence-wise part-of-speech (PoS) tagging using the moot tagger on the observations (word forms) provided by "dmoot" or the raw input token text and the morphological ambiguity classes supplied by "dmootsub" or "morph".
Sentence-wise post-processing for the "moot" tagger. Mostly useful for determining the "best" lemma for the canonical word form ("dmoot" or token text) and PoS-tag selected by by "moot" from the set of canonical morphological analyses ("dmootsub" or "morph").
This section describes the most common analysis attributes used by the default DTA::CAB::Chain::DTA configuration. Each attribute is described by a template such as:
data: $OBJ->{ATTR} = CODE
text: +[LABEL] TEXT
hidden: HIDDENwhere:
$OBJ->{ATTR} = CODE is Perl notation for the underlying data-structure of the attribute. $OBJ is one of $w, $s, or $doc to indicate a token-, sentence-, or document--level attribute, respectively. If unspecified, ATTR is identical to the attribute name itself, and CODE is a simple string containing the atomic attribute value.
+[LABEL] TEXT is the "Text"-Format notation for the corresponding attribute. If unspecified, LABEL is identical to the attribute name itself, and TEXT is a simple string containing the atomic attribute value. +[LABEL] ... indicates that the label LABEL can occur more than once per object -- this typically means that the corresponding attribute is list-valued.
HIDDEN indicates whether the attribute's value is suppressed in the output of the publicly accessible web-service. If unspecified, the attribute is not hidden.
The following attributes are used by the default DTA::CAB::Chain::DTA chain:
perl: $w->{dmoot} = { tag=>$CANON, analyses=>[ { tag=>$CANDIDATE, prob=>$COST }, ... ] }
text: +[dmoot/tag] CANON
+[dmoot/analysis] CANDIDATE <COST>
+[dmoot/analysis] ...HMM conflation candidate disambugiation supplied by the "dmoot" component. $CANON represents the "best" modern form for the input token "text", and the candidate conflations are represented by elements of the analyses array.
perl: $w->{eqphox} = [ { w=>$COST, hi=>$CANDIDATE }, ... ]
text: +[eqphox] CANDIDATE <COST>
+[eqphox] ...Phonetic conflation candidate(s) supplied by the "eqphox" component.
Exception lexicon entry (preferred modern form) for the input type ("text"), if any.
Error-ID from the DTA::CAB error database giving rise to the exception lexicon entry for the input type ("text"), if any. The errid attribute value may also be the designated string "ec", indicating that the exception lexicon entry was automatically generated from the DTA EvalCorpus.
Frequency of the surface type in the DTA corpus, if available.
Boolean integer indicating whether or not at least one "morph" analysis was present for the current token. Unlike the morph attribute, the hasmorph attribute is not suppressed in the output from the publicly accessible web-service.
perl: $w->{lang} = [ $LANG, ... ]
text: +[lang] LANG
+[lang] ...Language(s) in which the current token is known to occur, as determined by the "morph", "mlatin", and/or "lang" components.
perl: $s->{lang} = $LANG
text: %% $s:lang=LANGAs a sentence-attribute, lang indicates the single best guess source language for the sentence. The "best guess" is determined for each sentence by counting the total number of token "text" characters for each lang attribute value associated with any token in that sentence, and choosing the lang attribute value with the largest character count; the default fallback value for the DTA chain is "de" (i.e. German).
perl: $w->{lts} = { w=>$COST, hi=>$PHO }
text: +[lts] PHO <COST>Approximated phonetic form for the input type ("text"), as determined by the "lts" component.
perl: $w->{mlatin} = [ { w=>0, hi=>"[_FM][lat]" } ]
text: +[morph/lat] [_FM][lat] <0>Pseudo-morphological analysis returned by the "mlatin" component.
perl: $w->{moot} = { word=>$WORD, tag=>$TAG, lemma=>$LEMMA, details=>\%DETAILS, analyses=>\@ANALYSES }
text: +[moot/word] WORD
+[moot/tag] TAG
+[moot/lemma] LEMMA
+[moot/details] ...
+[moot/analysis] ...Represents the part-of-speech tag (TAG) supplied by the "moot" component and post-tagging lemmatization (LEMMA) provided by the "mootsub" component. For convenience, the sub-attribute WORD indicates the final "canonical" surface form which was ultimately used as input to the part-of-speech tagger, and thus CAB's bottom line best-guess regarding the "proper" extant equivalent word form for the input token "text". DETAILS and ANALYSES are suppressed in the output of the publicly accessible web-service.
perl: $w->{morph} = [ { w=>$COST, hi=>"$DEEP\[_$TAG]$FEATURES"}, ... ]
text: +[morph] DEEP [_TAG]FEATURES
+[morph] ...
hidden: yesMorphological analysis returned by the "morph" component. $DEEP is the "deep-form" of the corresponding lexical item, $TAG is a part-of-speech tag supplied by the morphological component, and $FEATURES are additional morphosyntactic features (if any).
perl: $w->{msafe} = $SAFE
text: +[morph/safe] SAFEMorphological security heuristics returned by the "msafe" component. $SAFE is a Boolean integer, where 0 (zero) indicates a "suspicious" type and 1 (one) indicates a "trustworthy" type.
If present, indicates that the surface form occurs in an Integrated Authority File (GND) record for at least one author whose work is included in the Deutsches Textarchiv core corpus. Probably not really very useful in general.
perl: $w->{rw} = [ { w=>$COST, hi=>$CANDIDATE }, ... ]
text: +[rw] CANDIDATE <COST>
+[rw] ...Rewrite conflation candidate(s) supplied by the "rw" component.
Raw UTF-8 surface token text as appearing in the input stream. If the input was untokenized and the source token was split over multiple input lines, then the text attribute will not contain the hyphen or line-break.
perl: $w->{xlit} = { isLatin1=>$IS_LATIN_1, isLatinExt=>$IS_LATIN_EXT, latin1Text=>$LATIN1_TEXT }
text: +[xlit] l1=IS_LATIN_1 lx=IS_LATIN_EXT l1s=LATIN1_TEXTDeterministic transliteration of input token "text" and associated properties provided by the "xlit" component. $IS_LATIN_1 is 1 (one) iff the input token "text" consists entirely of characters from the latin-1 subset, and otherwise 0 (zero). Similarly, $IS_LATIN_EXT is 1 (one) iff the input token "text" consists entirely of characters from the latin-1 subset and/or latin extensions, and otherwise 0 (zero). $LATIN1_TEXT is a Latin-1 transliteration of the token's "text" attribute.
The CAB web-service supports a number of different input- and output-formats for document data. This section presents a brief outline of some of the more popular formats. See "SUBCLASSES" in DTA::CAB::Format for a list of currently implemented format subclasses, and see the "Formats" link in the CAB web-service interface link area for a list of format aliases supported by the server. Formatted input documents are passed to the low-level service using the qd query parameter, the use of which is controlled by the tokenize option in the Query Form section of the graphical interface.
CAB supports various text-based formats for human consumption and/or further processing. While typically not as flexible or efficient as the "pure" data-oriented formats described below, CAB's native text-based formats offer a reasonable compromise between human- and machine-readability. All text-based CAB formats expect and return data encoded in UTF-8, without a Byte-order mark.
[example input, example output]
Format for "raw" unstructured, untokenized UTF-8 text, implicitly used for query strings passed in via the q parameter. Input will be tokenized with a language-specific WASTE model characteristic for the underlying DTA::CAB server (typically de-dta-tiger).
As an output format, DTA::CAB::Format::Raw writes all and only the canonical ("modern", "normalized") surface form of each token to the output stream. Individual output tokens are separated by a single space character (ASCII 0x20, " ") and individual output sentences are separated by a single newline character (ASCII 0x0A, "\n"). If you are interested only in modern lemmata (rather than surface forms), consider using the TAB-separated "CSV" format and projecting the 5th output column (LEMMA). If you are working from XML input such as "TEI" or "TEI-ling", consider using the default (information-rich) output format and post-processing it with the "ling2plain.xsl" stylesheet.
[example]
Simple human-readable text format as described under "Basic Usage", above. Blank lines indicate sentence boundaries, comments are lines beginning with "%%", a line with no leading whitespace contains the surface text of a new token (word), and subsequent token-lines are attribute values beginning with a TAB character and a plus sign ("+"), followed by the attribute label enclosed in square brackets "[...]" and the attribute value as a text-string.
Caveat: CAB's "Text" format is not "plain text" in the usual sense of an unstructured serial stream of character content: use the "Raw" format if you need to tokenize and analyze (UTF-8 encoded) plain text.
Primarily useful for direct inspection and debugging.
[example]
"Vertical" text format containing conforming to the CONLL-U format conventions as described under https://universaldependencies.org/format.html. Supports various additional annotations in the CONLL-U "MISC" field, including full dump of CAB-internal token structure as for the "TJ" format.
This may be a good choice for data interchange with other NLP tools which also support the CONLL-U format, but note that additional postprocessing will be required if you want CAB's canonical modern forms to appear in the CONLL-U "FORM" field.
[example]
Simple fixed-width "vertical" text format containing only selected attribute values. Each line is either a comment introduced by "%%", an empty line indicating a sentence boundary, or a TAB-separated token line. Token lines are of the form
SURFACE_TEXT XLIT_TEXT CANON_TEXT POS_TAG LEMMA ?DETAILSwhere SURFACE_TEXT is the surface form of the token, XLIT_TEXT is the result of a simple deterministic transliteration using unicruft, CANON_TEXT is the automatically determined canonical modern form for the token, POS_TAG is the part-of-speech tag assigned by the moot tagger, LEMMA is the modern lemma form determined for CANON_TEXT and POS_TAG by the TAGH morphological analyzer, and DETAILS if present are additional details.
This is the most compact of the text-based formats supported by CAB, but lacks flexibility.
[example]
Simple machine-readable "vertical" text format similar to that used by Corpus WorkBench. Each line is either a comment introduced by "%%", an empty line indicating a sentence boundary, or a TAB-separated token line. Each token line's initial column is the token surface text, and subsequent columns are are the token's attribute values, where each attribute value column begins with the attribute label enclosed in square brackets "[...]" and is followed by the attribute value as a text string, as for the "Text" format without the leading "+".
Useful for further quick and dirty script-based processing.
[example]
Simple machine-readable "vertical" text format based on the TT format but using JSON to encode sentence- and token-level attributes rather than an explicit attribute labelling scheme. Each line is either a comment introduced by "%%", an empty line indicating a sentence boundary, a document attribute line, a sentence attribute line, or a TAB-separated token line. Document-attribute lines are comments of the form "%%$TJ:DOC=JSON", where JSON is a JSON object representing auxilliary document attributes. Sentence-attribute lines are analogousd comments of the form "%%$TJ:SENT=JSON". Token lines consist of the the token surface text, followed by a TAB character, followed by a JSON object representing the internal token structure.
Useful for further script-based processing.
[example]
Format used for online term expansion by DDC Expand CAB. Parses pre-tokenized input using the "TT" format, and formats output as a flat list of expanded types separated by TABs, newlines, and/or carriage returns.
Primarily useful for online "Term Expansion" in conjunction with "Analysis Chains" such as expand, expand.eqlemma, expand.eqpho, or expand.eqrw.
The CAB web-service supports a number of XML-based formats for data exchange. XML data formats are in general less efficient to parse and/or generate than text-based or data-oriented formats, but they do retain some degree of human-readability and the easy availability of XML processing software packages such as libxml or XMLStarlet makes such formats reasonable candidates for archiving and cross-platform data sharing.
[example]
Simple serial XML-based format as used by the DTA::TokWrap module. Supports arbitrary token attribute substructure, but fairly slow.
[example]
Simple serial XML-based format as used by the DTA::TokWrap module. Faster than the XmlTokWrap formatter, but doesn't support all attributes.
[example]
Flat XML-based format similar to "XmlTokWrapFast" but using only TEI att.linguistic attributes to represent token information. Faster than the XmlTokWrap formatter, but doesn't support all attributes.
[example input, example output]
Parses raw un-tokenized TEI-like input (with or without //c elements) using DTA::TokWrap to reserialize and tokenize the source text, and splices analysis results into the resulting XML document using the XmlTokWrap format. Any <s> or <s> elements in the input will be ignored and the input will be (re-)tokenized. Output data is itself parseable by by the TEIws formatter.
Be warned that output sentence- and token-nodes (<s> and <w> elements, respectively) may be fragmented in the final output file. A "fragmented" node in this sense is a logical unit (sentence or token) realized in the output TEI-XML file as multiple elements. Fragmented nodes are encoded using the TEI "linking" attributes @prev and @next, and only the first element of a fragmented node should contain the CAB attribute substructure for that node.
Input to this class need not strictly conform to the TEI Guidelines; in fact, the only structural requirement is that at least one <text> element be present -- any input outside of the scope of a <text> element is ignored. Input files must however be encoded in UTF-8. In particular, XML documents conforming to the DTABf Guidelines should be handled gracefully.
Primarily useful for analyzing native TEI-like XML corpus data without losing structural information encoded in the source XML itself.
[example input, example output]
Wrapper for the "TEI" parser/formatter class using "XmlTokWrapFast" to format the low-level token data See "TEI" and "XmlTokWrapFast" for caveats.
[example input, example output]
Wrapper for the "TEI" parser/formatter class using "XmlLing" to format the low-level token data using only TEI att.linguistic attributes. See "TEI" and "XmlLing" for caveats.
[example input, example output]
High-level parser/formatter class for pre-tokenized (and possibly fragmented) TEI-like XML as output by the TEI formatter. Input files should be encoded in UTF-8, and every input sentence //s and token //w must have an @id or @xml:id attribute.
Potentially useful for analyzing pre-tokenized TEI-like XML data, but primarily used for converting to other, script-friendlier formats such as CSV.
[example]
Wrapper for the "TEIws" parser/formatter class using "XmlLing" to format the low-level token data using only TEI att.linguistic attributes, which are also parsed from the input document if present. See "TEIws" and "XmlLing" for caveats.
[example input (untokenized), example input (pre-tokenized), example output]
Monolithic stand-off XML format used by CLARIN-D, in particlar by the CLARIN-D WebLicht tool-chainer. See the TCF format documentation for details on the TCF format. CAB currently handles only the text, tokens, sentences, POStags, lemmas, and orthography TCF layers.
[example]
Flexible but obscenely inefficient format used for data transfer by the XML-RPC Protocol. Avoid it if you can.
The following formats provide direct dumps of the underlying DTA::CAB::Document used internally by CAB itself. They are efficient to parse and to produce, but may not be suitable for direct human consumption.
[example]
Direct JSON dump of the underlying DTA::CAB::Document structure using the Perl JSON::XS module. Very fast and flexible, suitable for further automated processing.
[example]
Direct dump of the underlying DTA::CAB::Document structure as YAML markup. Fast, flexible, and supports shared substructures, unlike the JSON formatter.
[example]
Direct dump of the underlying DTA::CAB::Document structure using the Perl Data::Dumper module. Mainly useful for further automated processing with Perl while retaining some degree of human readability.
[example]
Direct binary dump of the underlying DTA::CAB::Document structure using the Perl Storable module. This is currently the fastest I/O class for both in- and output, mainly useful for further automated processing with Perl.
If you have a source document you wish to pass to the CAB web-service which is not already encoded in a format supported directly by the web-service, you will first have to convert it to such a format before you can analyze it. The OxGarage conversion suite is particularly useful for such tasks, and is capable of producing TEI-XML or plain text from a number of popular document formats.
Similarly, if you find that none of the supported output formats suit your needs, you may need to perform additional conversion to the analysis data returned by the web-service: the CSV format can for example be imported into most spreadsheet programs, or you can use some third-party conversion software such as OxGarage or LibreOffice.
The CAB web-service is a request-oriented service: it accepts a user request as a set of parameter=value pairs and returns the analyzed data as a DTA::CAB::Document object encoded according to the output format specified by the ofmt parameter. Parameters are passed to the DiaCollo web-service RESTfully via the URL query string or HTTP POST request as for a standard web form. The URL for the low-level request including all user parameters is displayed in the web front-end in the status line. See "query Requests" in DTA::CAB::HttpProtocol for more details on the RESTful CAB request protocol and a list of supported parameters.
Since CAB requests are really nothing more than standard HTTP form requests, a large variety of existing software packages can be used to generate and dispatch CAB requests, e.g LWP::UserAgent, curl, or wget. When automating CAB requsts, please respect the caveats mentioned above in the file query example.
To analyze a TEI-like XML file FILE.tei.xml using curl and save the analysis results to a "spliced" TEI file FILE.teiws.xml, the following command-line ought to suffice:
curl -X POST -sSLF "qd=@FILE.tei.xml" -o "FILE.teiws.xml" "http://www.deutschestextarchiv.de/public/cab/query?fmt=tei"Alternative IO formats and request parameters can be accommodated by inserting them into the URL query string passed to curl. You can also make use of the inline POSTDATA mechanism (a.k.a. "xpost") described in the DTA::CAB::HttpProtocol manpage in order to save yourself and the CAB server the effort of encoding/decoding the document data. In this case, you need to specify an appropriate "Content-Type" header, e.g:
curl -X POST -sSLH "Content-Type: text/tei+xml; charset=utf8" --data-binary "@FILE.tei.xml" -o "FILE.teiws.xml" "http://www.deutschestextarchiv.de/public/cab/query?fmt=tei"You might be interested in the cab-curl-post.sh and/or cab-curl-xpost.sh wrapper scripts, which encapsulate some of the common curl command-line options. The preceding 2 example curl calls should be equivalent to:
bash cab-curl-post.sh "?fmt=tei" "FILE.xml" -o "FILE.teiws.xml"
bash cab-curl-xpost.sh "?fmt=tei" "FILE.xml" -o "FILE.teiws.xml"Note that when accessing the CAB web-service API directly via HTTP in this fashion, auto-detection of input file format is not supported, so you must specify at least the "fmt" parameter in the URL query string if your files are not in the global default format (usually TT).
The following XSL scripts are provided for post-processing the "spliced" TEI-like output format.
Removes native CAB-markup from TEI-like XML files, encoding the remaining token analysis information using the TEI att.linguistic inventory. All tokens remain encoded as <w> elements (rather than <pc> elements), and only the att.linguistic attributes @lemma, @pos, and @join are inserted, so that e.g.
<w id="w2" t="EJn"><moot word="Ein" lemma="ein" tag="ART"/>EJn</w>
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/>Elephant</w><w>!</w>becomes:
<w id="w2" lemma="ein" pos="ART" norm="Ein">Ein</w>
<w id="w3" join="right" lemma="Elefant" pos="NN" norm="Elefant">Elephant</w>
<w join="left">!</w>Note that the @join attribute will be correctly generated only if the relevant w elements are truly immediately adjacent in the input file: any intervening newlines or other whitespace will prohibit insertion of a @join attribute.
Removes //s and //w elements, replacing the surface text of each token with its CAB-normalized form, so that e.g.
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/><xlit isLatin1="1" latin1Text="Elephant" isLatinExt="1"/>Elephant</w>becomes simply the text node
ElefantRemoves //s and //w elements, replacing non-identity normalizations with a choice element containing a daughter orig with the original surface form and a reg[@resp="#cab"] daughter containing the CAB-normalized form, so that e.g.
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/><xlit isLatin1="1" latin1Text="Elephant" isLatinExt="1"/>Elephant</w>becomes
<choice><orig>Elephant</orig><reg resp="#cab">Elefant</reg></choice>Resolves fragmented nodes and converts a "spliced" TEI-like XML file into a serial format as output by the XmlTokWrap formatter class.
Removes some extraneous CAB-markup from TEI-like XML files. Probably not really useful for files returned by the CAB web-service.
Removes most CAB-markup from TEI-like XML files, so that e.g.
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/><xlit isLatin1="1" latin1Text="Elephant" isLatinExt="1"/>Elephant</w>becomes
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/>Elephant</w>Removes most CAB-markup from TEI-like XML files and assigns CAB-internal attributes to the XML namespace "cab" (http://deutschestextarchiv.de/ns/cab/1.0), so that e.g.
<w id="w3" t="Elephant"><moot word="Elefant" lemma="Elefant" tag="NN"/><xlit isLatin1="1" latin1Text="Elephant" isLatinExt="1"/>Elephant</w>becomes
<w xml:id="w3" cab:t="Elephant" cab:word="Elefant" cab:tag="NN" cab:lemma="Elefant">Elephant</w>The following XSL scripts are provided for post-processing the TEI-ling output format.
Variant of spliced2norm.xsl for use with "TEI-ling" input.
Variant of ling2norm.xsl which outputs plain (normalized) text rather than XML. Note that the output text is ALWAYS in strict TEI-document serial order, since this script does not respect any serialization hints encoded by TEI "linking" attributes or provided by DTA::TokWrap. If you want to ensure a linguistically plausible serial order, you should prefer a "flat" serial document format such as "XmlTokWrapFast" or "XmlLing".
Swaps the text content of 1:1-corresponding //tokens/token and //orthography/correction[@operation="replace"] elements, so that e.g.
<tokens>
<token ID="w1">Ein</token>
<token ID="w2">Elephant</token>
</tokens>
...
<orthography>
<correction tokenIDs="w2" operation="replace">Elefant</correction>
</orthography>becomes
<tokens>
<token ID="w1">Ein</token>
<token ID="w2">Elefant</token>
</tokens>
...
<orthography>
<correction tokenIDs="w2" operation="replace">Elephant</correction>
</orthography>Potentially useful for preparing CAB-annotated TCF data for submission to other text-sensitive TCF processors which themselves do not respect the //orthography layer.
The DTA::CAB source code distribution is available on CPAN.
You should be aware that the source code distribution alone is not sufficient to set up and run a complete DTA::CAB analysis pipeline on your local site. In order to do that, you would also need various assorted language models and additional resources which are not themselves part of DTA::CAB (which aspires to be language-agnostic), and therefore not part of the source code distribution. See Jurish (2012) and the source code documentation for more details.
The author would appreciate CAB users citing its use in any related publications. As a general CAB-related reference, and for analysis and canonicalizaion of historical text to modern forms in particular, you can cite:
Jurish, B. Finite-state Canonicalization Techniques for Historical German. PhD thesis, Universität Potsdam, 2012 (defended 2011). URN urn:nbn:de:kobv:517-opus-55789, [epub, PDF, BibTeX]
For the concrete architecture of the CAB system as used by the Deutsches Textarchiv (DTA) project, you can cite:
Jurish, B. "Canonicalizing the Deutsches Textarchiv." In Proceedings of Perspektiven einer corpusbasierten historischen Linguistik und Philologie (Berlin, Germany, 12th-13th December 2011), volume 4 of Thesaurus Linguae Aegyptiae, Berlin-Brandenburgische Akademie der Wissenschaften, 2013. [epub, PDF, BibTeX]
For online term expansion with the "expand" analysis chain, you can cite:
Jurish, B., C. Thomas, & F. Wiegand. "Querying the Deutsches Textarchiv." In U. Kruschwitz, F. Hopfgartner, & C. Gurrin (editors), Proceedings of the Workshop MindTheGap 2014: Beyond Single-Shot Text Queries: Bridging the Gap(s) between Research Communities Berlin, Germany, 4th March, 2014, pages 25-30, 2014. [PDF, BibTeX]
The CAB software page is the top-level repository for CAB documentation, news, etc.
The DTA::CAB source code distribution lives on CPAN.
The DTA::CAB manual page contains a basic introduction to the the CAB architecture.
The DTA::CAB::Format manual page describes the abstract CAB I/O Format API, and includes a list of supported format classes.
The DTA::CAB::HttpProtocol manual page describes the conventions used by the CAB web-service API.
The DTA 'Base Format' Guidelines (DTABf) describes the subset of the TEI encoding guidelines which can reasonably be expected to be handled gracefully by the CAB TEI and/or TEIws formatters.
Jurish (2012) describes the abstract method used by CAB for canonicalizaion of historical text to modern forms.
Jurish (2013) describes the concrete architecture of the CAB system as used by the Deutsches Textarchiv project.
Jurish et al. (2014) describes the use of CAB's online term expansion chain for runtime evaluation of database queries.
Bryan Jurish <jurish@bbaw.de>