#include "../CommonLib/utilit.h"#include "../AgramtabLib/agramtab_.h"#include "FormInfo.h"#include "OperationMeter.h"

Go to the source code of this file.
Classes | |
| struct | CParadigmInfo |
| struct | CPredictSuffix |
| struct | CMorphSession |
| struct | CDumpParadigm |
| class | MorphoWizard |
| struct | MorphoWizard::AncodeLess |
| class | MorphWizardMeter |
Typedefs | |
| typedef multimap< string, CParadigmInfo > | LemmaMap |
| typedef LemmaMap::iterator | lemma_iterator_t |
| typedef LemmaMap::const_iterator | const_lemma_iterator_t |
| typedef set< CPredictSuffix > | predict_container_t |
Functions | |
| BYTE | TransferReverseVowelNoToCharNo (const string &form, BYTE AccentCharNo, MorphLanguageEnum Language) |
Variables | |
| const WORD | UnknownSessionNo = 0xffff-1 |
| const WORD | UnknownPrefixSetNo = 0xffff-1 |
| const BYTE | UnknownAccent = 0xff |
| const WORD | AnyParadigmNo = 0xffff |
| const WORD | AnyAccentModelNo = 0xffff |
| const WORD | AnySessionNo = 0xffff |
| const WORD | AnyPrefixSetNo = 0xffff |
| const BYTE | AnyAccent = 0xff-1 |
| const char * | AnyCommonAncode |
| const int | MinPredictSuffixLength = 2 |
| const int | MaxPredictSuffixLength = 5 |
Typedef Documentation
◆ LemmaMap
| typedef multimap<string, CParadigmInfo> LemmaMap |
◆ lemma_iterator_t
| typedef LemmaMap::iterator lemma_iterator_t |
◆ const_lemma_iterator_t
| typedef LemmaMap::const_iterator const_lemma_iterator_t |
◆ predict_container_t
| typedef set<CPredictSuffix> predict_container_t |
Function Documentation
◆ TransferReverseVowelNoToCharNo()
| BYTE TransferReverseVowelNoToCharNo | ( | const string & | form, |
| BYTE | AccentCharNo, | ||
| MorphLanguageEnum | Language | ||
| ) |
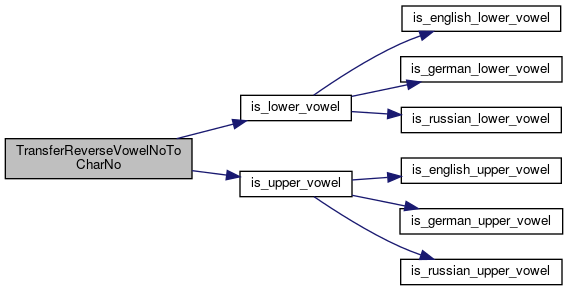
References is_lower_vowel(), is_upper_vowel(), and UnknownAccent.
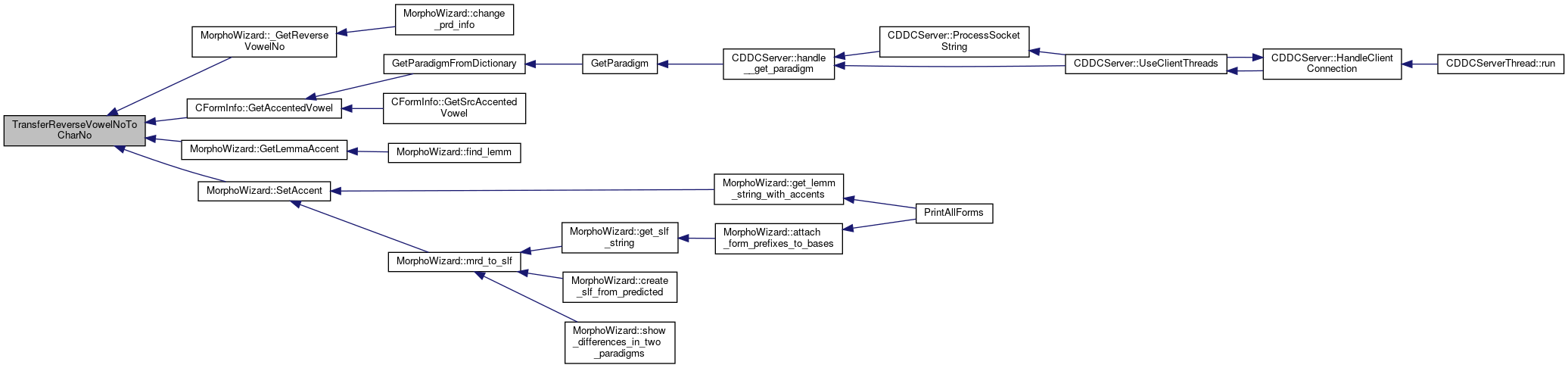
Referenced by MorphoWizard::_GetReverseVowelNo(), CFormInfo::GetAccentedVowel(), MorphoWizard::GetLemmaAccent(), and MorphoWizard::SetAccent().
Variable Documentation
◆ UnknownSessionNo
| const WORD UnknownSessionNo = 0xffff-1 |
◆ UnknownPrefixSetNo
| const WORD UnknownPrefixSetNo = 0xffff-1 |
◆ UnknownAccent
| const BYTE UnknownAccent = 0xff |
Referenced by MorphoWizard::_GetReverseVowelNo(), MorphoWizard::change_prd_info(), CParadigmInfo::CParadigmInfo(), MorphoWizard::create_slf_from_predicted(), MorphoWizard::find_lemm_by_accent_model(), CFormInfo::GetAccentedVowel(), MorphoWizard::GetLemmaAccent(), MorphoWizard::HasUnknownAccents(), MorphoWizard::IsPartialAccented(), ReadLemmas(), MorphoWizard::SetAccent(), MorphoWizard::show_differences_in_two_paradigms(), MorphoWizard::slf_to_mrd(), and TransferReverseVowelNoToCharNo().
◆ AnyParadigmNo
| const WORD AnyParadigmNo = 0xffff |
Referenced by CParadigmInfo::AnyParadigmInfo(), and CParadigmInfo::IsAnyEqual().
◆ AnyAccentModelNo
| const WORD AnyAccentModelNo = 0xffff |
Referenced by CParadigmInfo::AnyParadigmInfo(), and CParadigmInfo::IsAnyEqual().
◆ AnySessionNo
| const WORD AnySessionNo = 0xffff |
Referenced by CParadigmInfo::AnyParadigmInfo().
◆ AnyPrefixSetNo
| const WORD AnyPrefixSetNo = 0xffff |
Referenced by CParadigmInfo::AnyParadigmInfo(), and CParadigmInfo::IsAnyEqual().
◆ AnyAccent
| const BYTE AnyAccent = 0xff-1 |
Referenced by CParadigmInfo::AnyParadigmInfo(), and CParadigmInfo::IsAnyEqual().
◆ AnyCommonAncode
| const char* AnyCommonAncode |
Referenced by CParadigmInfo::AnyParadigmInfo(), and CParadigmInfo::IsAnyEqual().
◆ MinPredictSuffixLength
| const int MinPredictSuffixLength = 2 |
Referenced by MorphoWizard::CreatePredictIndex(), and MorphoWizard::predict_lemm().
◆ MaxPredictSuffixLength
| const int MaxPredictSuffixLength = 5 |
Referenced by MorphoWizard::CreatePredictIndex(), and MorphoWizard::predict_lemm().
